We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
This section of our documentation is for Similarity Check account administrators who are integrating iThenticate v2 with their Manuscript Submission System (MTS).
Not sure if you’re using iThenticate v1 or iThenticate v2? More here.
Not sure whether you’re an account administrator? Find out here.
To set up your integration, you need to create an API key by logging into iThenticate through the browser. You will then share this API key and the URL of your iThenticate v2 account with your MTS.
Step One: Decide how many API scopes and API keys you need
Within iThenticate, you can set up different API Scopes, and within that, different API keys. Most members will just need one API Scope and one API key. However, some members may need more than one.
If you need to integrate with more than one Manuscript Tracking System (MTS), you will need a different API Scope for each MTS.
If you publish on behalf of societies or work with other organizations who want to keep their activities separate from each other, you will need a different API Scope and API key for each society.
If at some point in the future, you need to change your API key for an existing MTS integration, you must generate a new API key under the same scope that you originally used for this integration.
Step Two: Create your API Scope and API key(s)
Click on “Integrations” in the menu.
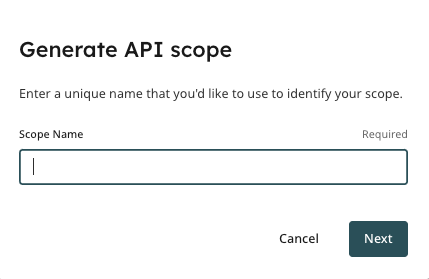
This will bring you to the Integrations section. Click on the “Generate API Scope” key.
You will then give your API Scope a name.
For example, this may be the name of a particular MTS, or of a particular society.
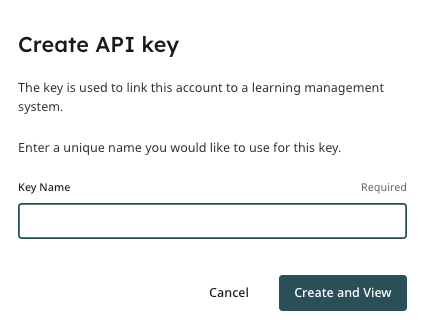
Under your new API Scope, you can then set up your first API key.
Once you add the key name, you will be able to click on the “Create and view” button. The system will then generate your key.
Step three: Add your API key into your Manuscript Tracking System (MTS)
In order to integrate your new iThenticate v2 account and your Manuscript Tracking system(s), your MTS will require from you:
At least one API key
Your unique iThenticate URL containing your Crossref membership number using the following format: https://crossref-xxx.turnitin.com. (For example, if your Crossref Membership number is 1234, your URL will be: https://crossref-1234.turnitin.com. If you are not sure what your Crossref Membership number is, please ask us.
Follow the instructions below for the relevant MTS:
Editorial Manager
Enter your iThenticate API key(s) and your iThenticate v2 account URL into the iThenticate configuration page in Editorial Manager. There are instructions available from Aries Systems here.
eJournal Press
Email your API key(s) and your iThenticate v2 account URL to support@ejpress.com and the team at eJournal Press will set up the integration for you.
ScholarOne
If you are already using iThenticate with ScholarOne and are upgrading from iThenticate v1 to iThenticate v2, please email your API key(s) and your iThenticate v2 account URL to s1help@clarivate.com, and the team at ScholarOne will make the change for you. Please put “Product Management” in the subject line of your email.
If you are a new subscriber to Similarity Check and you haven’t used iThenticate before, you don’t need to email the team at ScholarOne. Just enter your iThenticate API key(s) and your iThenticate v2 account URL into the iThenticate configuration page in ScholarOne.
Scholastica
The team at Scholastica will set up the integration for you. Give them your API key(s) and your iThenticate v2 account URL by filling out this form.
The team at Scholastica will also set up any exclusions for you, so in the form they’ll ask you which sort of content you want to exclude from displaying as a match.
Page owner: Kathleen Luschek | Last updated 2022-July-18