Today, we’re delighted to let you know that Crossref members can now use ROR IDs to identify funders in any place where you currently use Funder IDs in your metadata. Funder IDs remain available, but this change allows publishers, service providers, and funders to streamline workflows and introduce efficiencies by using a single open identifier for both researcher affiliations and funding organizations.
As you probably know, the Research Organization Registry (ROR) is a global, community-led, carefully curated registry of open persistent identifiers for research organisations, including funding organisations.
We began our Global Equitable Membership (GEM) Program to provide greater membership equitability and accessibility to organizations in the world’s least economically advantaged countries. Eligibility for the program is based on a member’s country; our list of countries is predominantly based on the International Development Association (IDA). Eligible members pay no membership or content registration fees. The list undergoes periodic reviews, as countries may be added or removed over time as economic situations change.
Retractions and corrections from Retraction Watch are now available in Crossref’s REST API. Back in September 2023, we announced the acquisition of the Retraction Watch database with an ongoing shared service. Since then, they have sent us regular updates, which are publicly available as a csv file. Our aim has always been to better integrate these retractions with our existing metadata, and today we’ve met that goal.
This is the first time we have supplemented our metadata with a third-party data source.
As a provider of foundational open scholarly infrastructure, Crossref is an adopter of the Principles of Open Scholarly Infrastructure (POSI). In December 2024 we posted our updated POSI self-assessment. POSI provides an invaluable framework for transparency, accountability, susatinability and community alignment. There are 21 other POSI adopters.
Together, we are now undertaking a public consultation on proposed revisions for a version 2.0 release of the principles, which would update the current version 1.
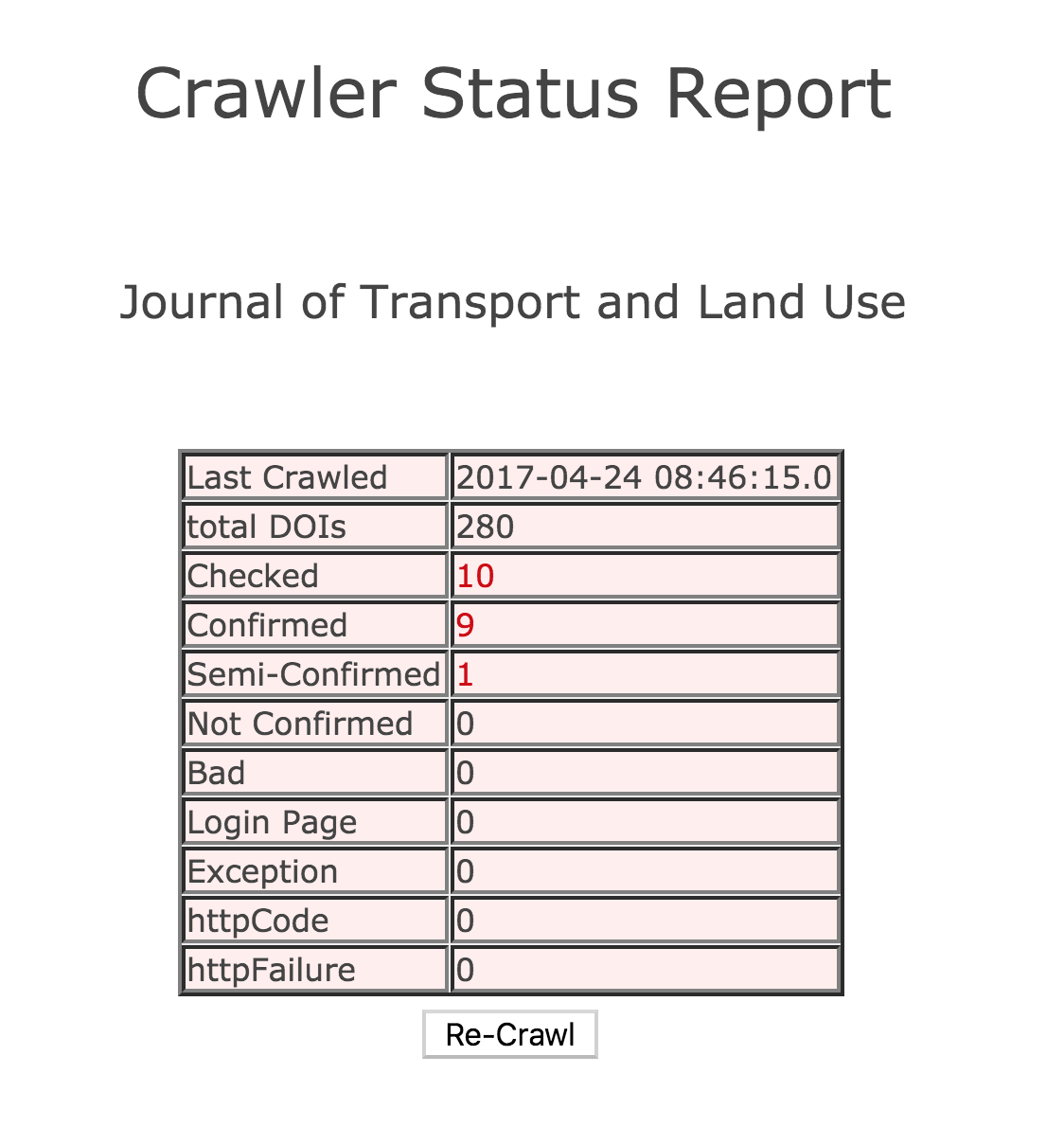
We test a broad sample of DOIs to ensure resolution. For each journal crawled, a sample of DOIs that equals 5% of the total DOIs for the journal up to a maximum of 50 DOIs is selected. The selected DOIs span prefixes and issues.
The results are recorded in crawler reports, which you can access from the depositor report expanded view (access the depositor reports by type at the links below).