We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
One of the main motivators for funders registering grants with Crossref is to simplify the process of research reporting with more automatic matching of research outputs to specific awards. In March 2022, we developed a simple approach for linking grants to research outputs and analysed how many such relationships could be established. In January 2023, we repeated this analysis to see how the situation changed within ten months. Interested? Read on!
TL;DR
The overall numbers changed a lot between March 2022 and January 2023:
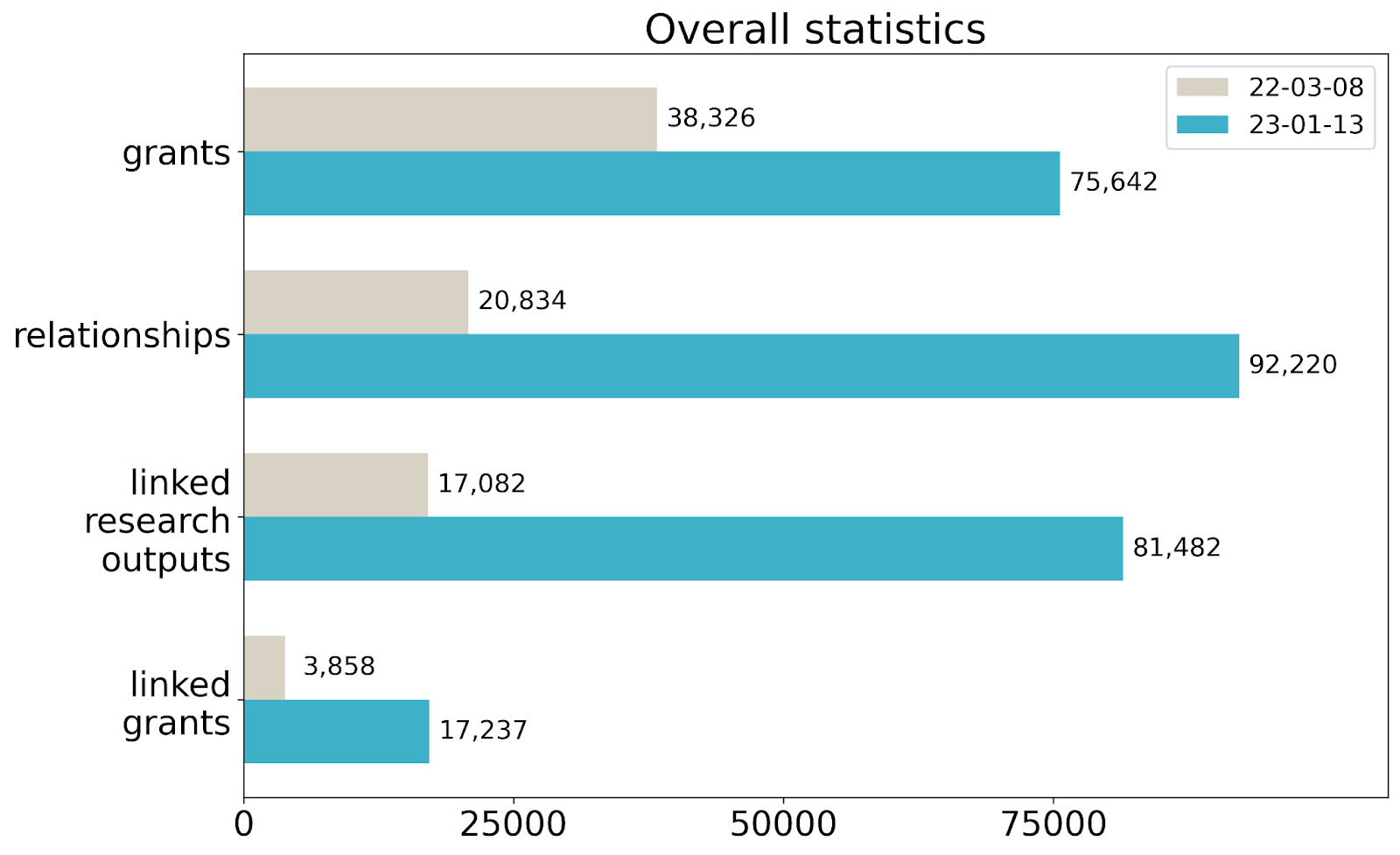
the total number of registered grants doubled (from ~38k to ~76k)
the total numbers of relationships established between grants and research outputs quadrupled (from 21k to 92k)
the percentage of linked grants increased substantially (from 10% to 23%)
Most of this growth can be attributed to one funder, the European Union. They started registering grants with us in December 2022, and:
their grants constitute 47% of all grants registered by January 2023 and 95% of grants registered between March 2022 and January 2023
72% of all established relationships involve their grants
We have further work planned both internally and with the community to consolidate and build out important relationships between funding and research outputs.
Introduction
When we started to develop, think and talk about grant registration at Crossref back in 2017, one of the key things we expected this to support was easier, more efficient, accurate analysis of research outputs funded by specific awards.
This is backed up by conversations with funders who are keen to fill in gaps in the map of the research landscape with new data points and better quality information, search for grants, investigators, projects or organisations associated with awards and simplify the process of research reporting and with automatic matching of outputs to grants.
To meet these expectations, we need not only identifiers and metadata of grants, but also relationships between them and research outputs supported by them. Unfortunately, our schema does not make it easy to directly deposit such relationships, and so there are only a handful of them available. But we wouldn’t let such a minor obstacle stop us! In March 2022 we analysed the metadata of registered grants and developed a simple matching approach to automatically link grants to research outputs supported by them. Back then, we were able to find 20,834 relationships, involving 17,082 research outputs and 3,858 grants (which was 10% of all registered grants).
Now that we are seeing the accumulation of grant metadata being registered with Crossref, we have a bigger dataset to test these expectations against than we did a year ago. So we decided to do the analysis again. And the results are in, they’re open, and they’re positive. We’ll explain below.
The methodology
To spare you from having to read the old analysis in detail, here is a very brief summary of the matching methodology. To find relationships between grants and research outputs, we iterated over all registered grants, and for each grant we searched for research outputs that looked like they might have been supported by this grant. We established a relationship between a grant and a research output if one of the following three scenarios was true:
The research output contained the DOI of the grant (deposited as the award number).
The award number in the grant was the same as the award number in the research output, the research output contained the funder ID, and one of the following was true: a. Funder ID in the grant was the same as the funder ID in the research output b. Funder ID in the grant replaced or was replaced by the funder ID in the research output c. Funder ID in the grant was an ancestor or the descendant of the funder ID in the research output
The award number in the grant was the same as the award number in the research output, the research output did not contain the funder ID, and one of the following was true: a. Funder name in the research output was the same as the funder name in the grant b. Funder name in the research output was the same as the name of a funder that replaced or was replaced by the funder in the grant c. Funder name in the research output was the same as the name of an ancestor or a descendant of the funder in the grant
Note that the replaced/replaced-by relationships and ancestor/descendant hierarchy are taken from the Funder Registry.
Current results
Since March 2022, six additional funders have started registering grants with us. As a result, the total number of grants doubled, and the total number of established relationships between grants and research outputs, linked grants, and linked research outputs quadrupled. Here is the comparison of the total numbers of grants, established relationships, linked grants, and linked research outputs in March 2022 and in January 2023:
95% of grants registered within ten months between March 2022 and January 2023 were registered by one funder: the European Union. This suggests that this funder contributed a lot to this rapid increase in the number of established relationships. It looks like this funder’s grant metadata is of high quality and matches well the funding information given in the research outputs supported by this funder’s grants.
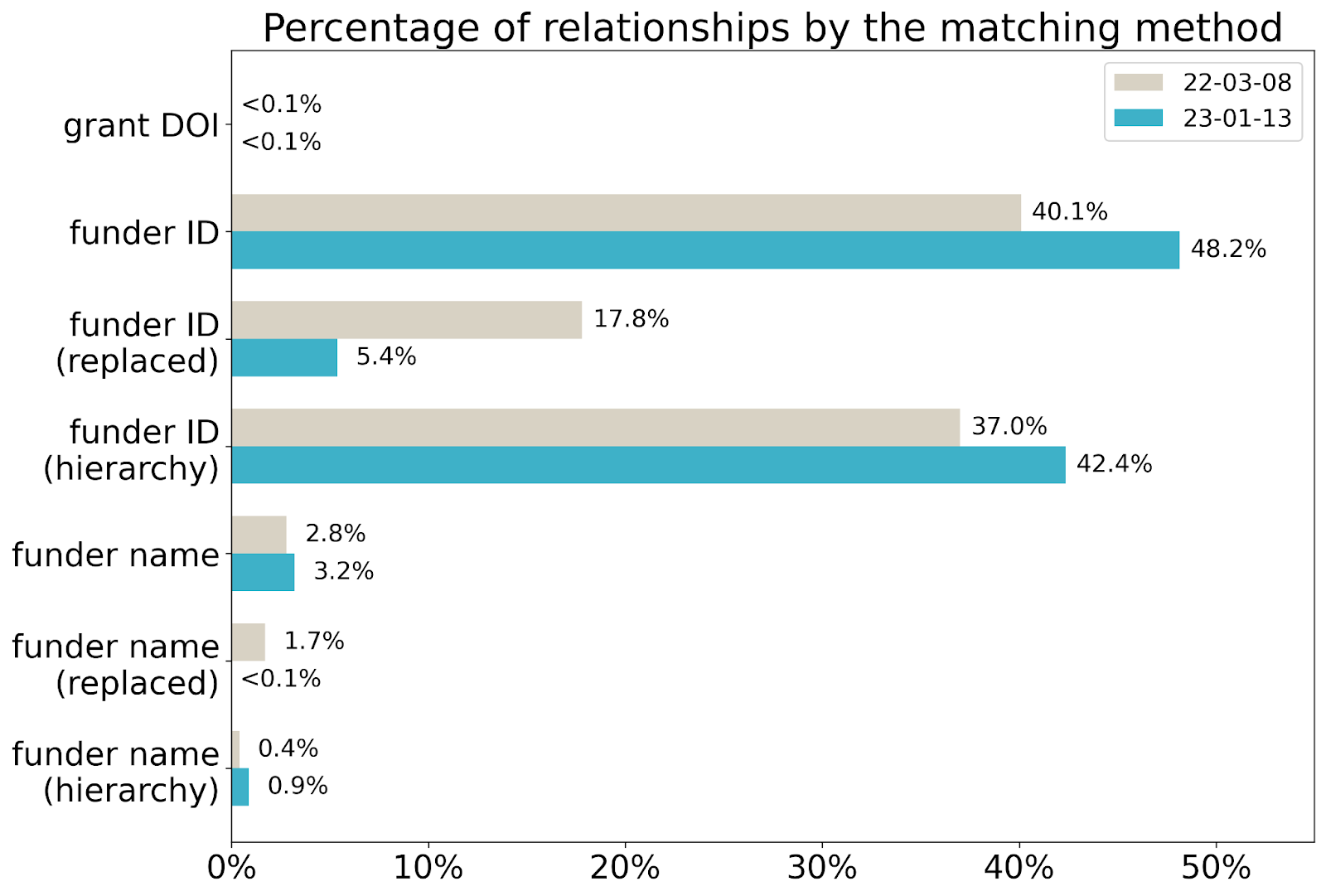
Let’s also compare the breakdowns of all established relationships by the matching method:
The distributions are a bit different. Currently, the percentage of relationships established based on the replaced/replaced-by relationship is much smaller than before, suggesting that newer data uses correct funder IDs instead of deprecated ones. Also, the percentage of the relationships matched by the funder ID increased from 40% to 48%, which is great, because this is the most reliable way of matching.
And here we have the statistics broken down by grant registrants. Only funders with at least 100 registered grants are included. The table shows the number of relationships, grants, linked grants, and linked research outputs, and is sorted by the percentage of linked grants.
funder
relationships
linked research outputs
grants
linked grants
European Union
66,562
60,630
35,530
12,688 (36%)
Gordon and Betty Moore Foundation
93
92
113
33 (29%)
Japan Science and Technology Agency (JST)
15,584
13,464
9,923
2,323 (23%)
James S. McDonnell Foundation
519
513
577
121 (21%)
Melanoma Research Alliance
188
185
425
82 (19%)
Muscular Dystrophy Association
50
50
178
25 (14%)
Parkinson’s Foundation
30
29
107
15 (14%)
Asia-Pacific Network for Global Change Research
127
127
560
70 (13%)
The ALS Association
96
90
477
58 (12%)
Wellcome
8,868
6,436
17,537
1,735 (10%)
American Cancer Society
19
19
266
15 (6%)
Templeton World Charity Organization
2
2
281
2 (0.7%)
Office of Scientific and Technical Information (OSTI)
73
69
8,723
62 (0.7%)
Children’s Tumor Foundation
1
1
662
1 (0.1%)
There are substantial differences between the percentages of linked grants from different funders. One of the newest registrants, the European Union, is at the top of the table with 36% of their grants linked to research outputs. This further confirms the high quality of the metadata registered by this member. It is worth noticing that this member is responsible for the majority of the growth reported here as they cover Horizon Europe, the European Research Council, and many other funding bodies and schemes.
Why are these percentages so low for some funders? It could be caused by systematic discrepancies between the award numbers attached to the grants and those reported in research outputs. It could also be the case that most grants registered by a given funder are new grants, and the research outputs supported by them simply have not been published yet. Time will tell!
What’s next
We’re dedicating lots of time in 2023 to examine, evolve, and expose the matching we do and can do at Crossref across different metadata fields. We then plan to incorporate matching improvements into our services so that everyone can benefit.
This isn’t a standalone piece of work. As you can see, the more award metadata we have connected to grants by funders and connected to outputs by those who post or publish research, the better we’ll be able to do this. To make it easier for more funders to participate, and based on funder feedback, we’ve built a simple tool for members to register their grants. We will also work to help incorporate grant identifiers into publishing and funder workflows, and further our discussions with the funders in our Funder Advisory Group and the wider community, including working together with the Open Research Funders Group, the HRA, Altum, Europe PMC, the OSTP, and the ORCID Funder Interest Group. And there will be more to come as we work together to consolidate and build out important relationships between funding and outputs - for everyone.
Follow-up
Every new thing takes time to get off the ground and to show evidence of its value. We’ve seen a significant step forward recently with funders joining and contributing to the research nexus. Publishers have been contributing funding data for years, and it’s now becoming much clearer to see how these two communities and these two sets of metadata are coming together to make research smoother and easier to manage and evaluate. If you are ready to register grants, talk about linking up your outputs, or just want to learn more about this work, we’d love to hear from you.