4 minute read.Introducing the Crossref Labs DOI Chronograph
tl;dr http://chronograph.labs.crossref.org
At Crossref we mint DOIs for publications and send them out into the world, but we like to hear how they’re getting on out there. Obviously, DOIs are used heavily within the formal scholarly literature and for citations, but they’re increasingly being used outside of formal publications in places we didn’t expect. With our DOI Event Tracking / ALM pilot project we’re collecting information about how DOIs are mentioned on the open web to try and build a picture about new methods of citation.
As part of the preparation for collaborating with Wikipedia, we looked at our statistics about when DOIs are clicked and discovered that Wikipedia was, over a two year period from 2012, the eighth largest referrer of DOIs. This means that not only does Wikipedia have a lot of DOIs, but people click them too. This bit of one-off data analysis (which surprised us) gave us enough of a prod to kickstart our collaboration with Wikipedia.
At the ALM Workshop 2014 in San Francisco we talked to some Wikipedians and bibliometricians and realised that we were sitting on a really interesting data-set and that it would be churlish not to share it. At the hackathon (read the report here) we started work on a service to gather information about DOIs and, a month later, we’re ready to unveil the DOI Chronograph.
Show me the goods
You can see:
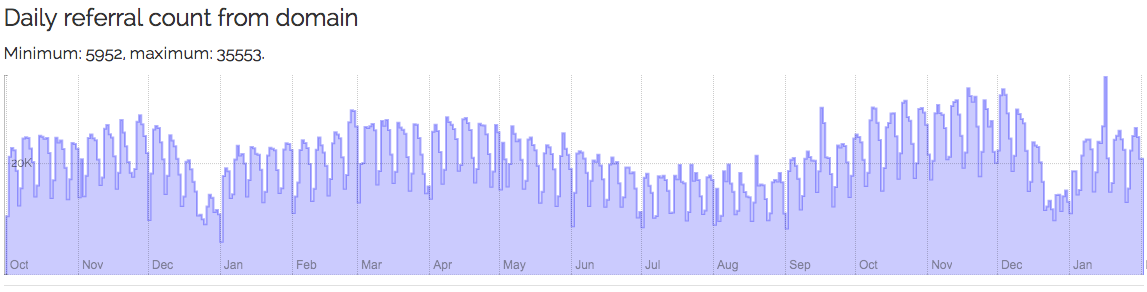
Daily referrals (clicks) from top level domains, e.g. Wikipedia.org: http://0-chronograph-labs-crossref-org.library.alliant.edu/domain.html?domain=wikipedia.org
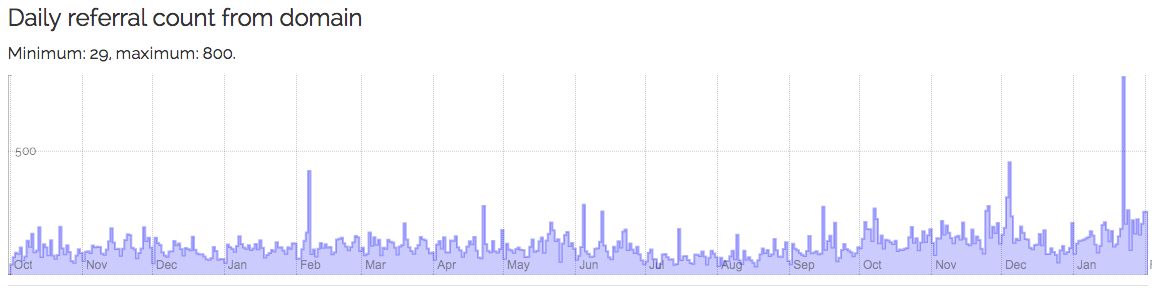
Daily referrals from specific subdomains, e.g. fr.wikipedia.org: http://0-chronograph-labs-crossref-org.library.alliant.edu/domain.html?domain=fr.wikipedia.org
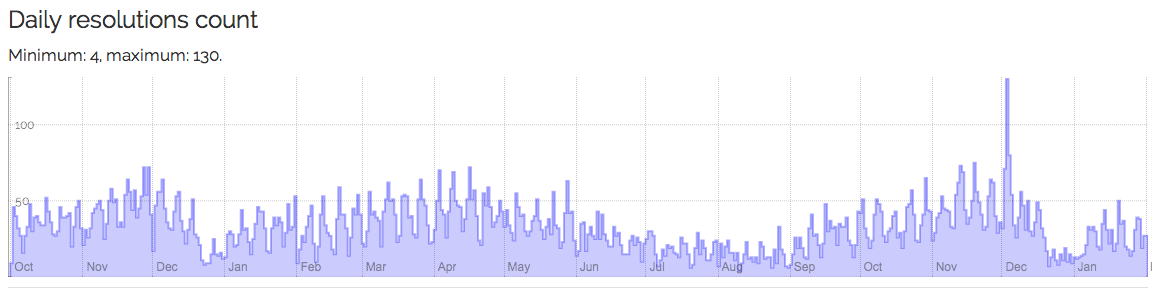
Daily resolutions per DOI: http://0-chronograph-labs-crossref-org.library.alliant.edu/doi.html?doi=10.1787%2F20752288
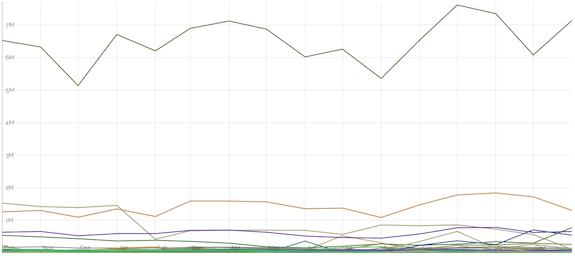
And, the chart that kicked this all off: DOI referring domains league tables. This shows that Wikipedia is the 3rd or 4th non-traditional referrer of DOIs (i.e. excluding referrals from Publishers’ domains): http://0-chronograph-labs-crossref-org.library.alliant.edu/top.html
Try it out
Visit the Chronograph and give it a try chronograph.labs.crossref.org on your favourite DOI (everyone has one).
More data
Talking to a bibliometrician we also realised we can correlate other data for DOIs. We’re getting the issue date (approximately the publication date) from our own metadata, as well as the date that the Crossref metadata was updated. This gives interesting results, like the resolutions for 10.1038/ncomms2953, which peak after publication and then tails off. We are attempting to collect the following information:
- daily resolution counts
- day on which resolution was first successful
- day on which it’s possible to resolve the DOI (we’ve got a bot running for new publications)
- day on which the publisher says the article was published
- day on which the metadata was most recently deposited with us
- day on which the metadata was first deposited with us
We’re not there yet, but we’ve made a start and we’ve already got some pretty interesting data!
Weasel words
It’s a labs project so the usual weasel words apply. Specifically, we currently have the logs for 2012 to 2014 (we’re working at digging out the rest), and the referral information for 50 million DOIs (out of 71 million). That number will be higher by the time you read this. If your page is slow to load, be patient, as it’s currently working hard crunching numbers.
This project is focused on exploring the use of DOIs outside of the formal literature. As such, we are only looking at referrals from domains that do not appear to belong to primary publishers (i.e. our members). If you try a domain and it doesn’t work, it could be that the domain belongs to one of our members. If you’ve notice any mistakes, please email us at labs@crossref.org .
Finally, these numbers contain all DOI resolutions. That’s human clicks but also content negotiation to retrieve metadata, robots etc. We might try to filter them in future, but for now be aware that not every visitor is a human.
I’ll detail some of the the technical stuff (it’s very interesting) and what happened next with Wikipedia in a future post. Watch this space.
Related pages and blog posts



