7 minute read.DOI: What Do We Got?
(Click image for full size graphic.)
Following the JISC seminar last week on persistent identifiers (#jiscpid on Twitter) there was some discussion about DOI and its role within a Linked Data context. John Erickson has responded with a very thoughtful post DOIs, URIs and Cool Resolution, which ably summarizes how the current problem with DOI in that the way the DOI is is implemented by the handle HTTP proxy may not have kept pace with actual HTTP developments. (For example, John notes that the proxy is not capable of dealing with ‘Accept’ headers.) He has proposed a solution, and the post has attracted several comments.
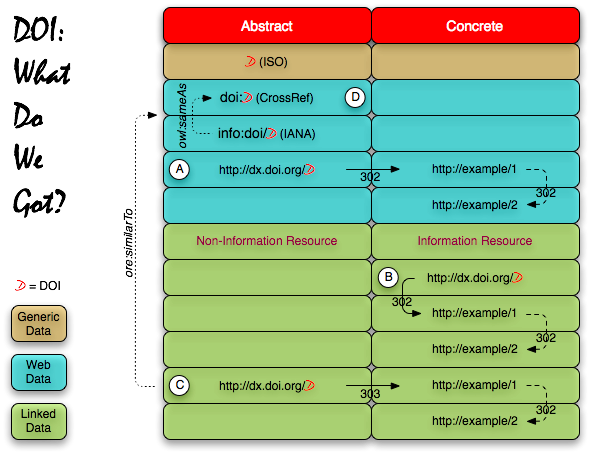
I just wanted to offer here the above diagram in an attempt to corral some of the various facets relating to DOI that I am aware of. I realize that this may seem like an open invitation to flame on - and this is a very preliminary draft - but … be kind!
So, this may be totally off the wall but it represents my best understanding of DOI as used by Crossref.
I have distinguished three main contexts:
- Generic Data - A generalized information context where the an object is identified with a DOI, an identifier system that is currently being ratified through the ISO process. This is the raw DOI number. (This definitely is not a first class object on the Web as it has no URI.)
- Web Data - An online information context (here I use the term ‘Web’ in its widest sense) where resources are identified by URI (not necessarily an HTTP URI). Here DOI is represented under two URI schemes: ‘doi:’ (unregistered but preferred by Crossref), and ‘info:’ (registered and available for general URI use). Also it has a presence on the Web via an HTTP proxy (dx.doi.org) URL where it is used as a slug to create a permalink (as listed at ‘A’). A simple HTTP redirect is used (with status code 302) to turn this permalink into the publisher response page http://example/1. (Note that typically a second redirect will occur on the publisher platform, here shown by the redirect to http://example/2.)
So how do we relate the DOI HTTP URI with the abstract (‘work’) identifier listed at ‘D’ in the diagram?
Well the Architecture of the World Wide Web recognizes two distinct classes of resources: Information Resources (IR) and Non-Information Resources (NR). (Note: Only the term ‘information resource’ is used in AWWW.) IR are those that can be directly retrieved using HTTP, whereas NR are not directly retrievable but have an associated description which is retrievable and is itself a proxy for the real world object.
So either the HTTP URI denotes an IR (as listed at ‘B’) and is resolved (through HTTP status code ‘302 Found’) to a default representation, which is the view that the Linked Data community would currently have of DOI. But this is at odds with what the Crossref position which regards DOI as identifying the abstract work. Alternately to fit better the Crossref model of DOI the HTTP URI would denote an NR (as listed at ‘A’) which would be resolved (through HTTP status code ‘303 See Other’) to an associated description - a publisher response page.
There will be those self-appointed URI czars who will bemoan the fact of there being multiple URIs. But frankly there is nothing inherently wrong with that. Just as in the real world there are many languages so in the online world there are multiple contexts and histories. We can attempt to make some sense of this by making use of the well-known semantic properties owl:sameAs and ore:similarTo and declare (as also shown in the diagram) the following assertions:
``
(Click image for full size graphic.)
Following the JISC seminar last week on persistent identifiers (#jiscpid on Twitter) there was some discussion about DOI and its role within a Linked Data context. John Erickson has responded with a very thoughtful post DOIs, URIs and Cool Resolution, which ably summarizes how the current problem with DOI in that the way the DOI is is implemented by the handle HTTP proxy may not have kept pace with actual HTTP developments. (For example, John notes that the proxy is not capable of dealing with ‘Accept’ headers.) He has proposed a solution, and the post has attracted several comments.
I just wanted to offer here the above diagram in an attempt to corral some of the various facets relating to DOI that I am aware of. I realize that this may seem like an open invitation to flame on - and this is a very preliminary draft - but … be kind!
So, this may be totally off the wall but it represents my best understanding of DOI as used by Crossref.
I have distinguished three main contexts:
- Generic Data - A generalized information context where the an object is identified with a DOI, an identifier system that is currently being ratified through the ISO process. This is the raw DOI number. (This definitely is not a first class object on the Web as it has no URI.)
- Web Data - An online information context (here I use the term ‘Web’ in its widest sense) where resources are identified by URI (not necessarily an HTTP URI). Here DOI is represented under two URI schemes: ‘doi:’ (unregistered but preferred by Crossref), and ‘info:’ (registered and available for general URI use). Also it has a presence on the Web via an HTTP proxy (dx.doi.org) URL where it is used as a slug to create a permalink (as listed at ‘A’). A simple HTTP redirect is used (with status code 302) to turn this permalink into the publisher response page http://example/1. (Note that typically a second redirect will occur on the publisher platform, here shown by the redirect to http://example/2.)
So how do we relate the DOI HTTP URI with the abstract (‘work’) identifier listed at ‘D’ in the diagram?
Well the Architecture of the World Wide Web recognizes two distinct classes of resources: Information Resources (IR) and Non-Information Resources (NR). (Note: Only the term ‘information resource’ is used in AWWW.) IR are those that can be directly retrieved using HTTP, whereas NR are not directly retrievable but have an associated description which is retrievable and is itself a proxy for the real world object.
So either the HTTP URI denotes an IR (as listed at ‘B’) and is resolved (through HTTP status code ‘302 Found’) to a default representation, which is the view that the Linked Data community would currently have of DOI. But this is at odds with what the Crossref position which regards DOI as identifying the abstract work. Alternately to fit better the Crossref model of DOI the HTTP URI would denote an NR (as listed at ‘A’) which would be resolved (through HTTP status code ‘303 See Other’) to an associated description - a publisher response page.
There will be those self-appointed URI czars who will bemoan the fact of there being multiple URIs. But frankly there is nothing inherently wrong with that. Just as in the real world there are many languages so in the online world there are multiple contexts and histories. We can attempt to make some sense of this by making use of the well-known semantic properties owl:sameAs and ore:similarTo and declare (as also shown in the diagram) the following assertions:
``
Note that ore:similarTo (stemming from the OAI-ORE work) is a weaker kind of relationship than owl:sameAs (which comes from OWL) and may be appropriate in this usage.
In sum, scenario ‘A’ is what we have currently implemented, scenario ‘B’ is what might be commonly perceived as being implemented, and scenario ‘C’ may be a more correct semantic position.
Your comments (and not unkind comments, please;) are more than welcome.




